本記事は新宅が執筆しています。今回は第 2 回社内 LT で発表した内容を記事にしています。
皆さんこんにちは。大変暑い中ですが、皆様いかがお過ごしでしょうか。青森市はようやく朝晩は涼しくなってきました。
また、全国各地で豪雨災害が極めて増加している関係で、冠水・浸水害・土砂災害が多発しております。被害に遭われた方々にはお見舞い申し上げます。青森市では、先月末に一度だけ、青森市の端の地域にレベル 4 の避難指示が発表され、緊急速報メールがけたたましく鳴るということがありましたが、市内では幸い被害はほとんどなかったようです。
さて、今回は第 2 回の社内 LT で発表した内容である「LM Studio における GPT-OSS の性能について」です。
社内 LT の様子については、下記のニュース記事にてご覧ください。
GPT-OSS って何?
生成 AI に少しでも興味がある方であれば言わずともご存知だとは思いますが、米 OpenAI 社が 2025/8/5 にリリースしたオープン ウェイト言語モデルで、計算リソースがあればローカルでも動作可能な言語モデル (LLM) でもあります。
https://openai.com/ja-JP/index/introducing-gpt-oss/
GPT-4o や GPT-5 などは OpenAI 社の ChatGPT や Microsoft Azure OpenAI サービスなどのクラウド サービスを有料で使用する必要がありますが、GPT-OSS はローカルでも動くことにより、適切な CPU や GPU さえ用意すれば、あとはその電気代のみで手元で AI を動かせるということで話題となりました。また、一度 GPT-OSS のモデルのダウンロードさえ完了してしまえばローカルのみで動くため、外部への情報流出の懸念を最小限に抑えられ、さらに極端な話をすると、どんな山奥でも電源さえあれば動かせるというメリットがあります。
大規模サーバー向けの gpt-oss-120b, PC など小規模向けの gpt-oss-20b の 2 種類が用意されています。b は billion の略で、10 億のことです。つまり、120b は 1200 億のパラメータが用意されており、科学計算用の高価な GPU が必要なほど性能が要求されるものの精度が高いです。20b は 200 億のパラメータが用意されており、120b に比べれば多少精度が落ちるもののハイエンドなゲーミング PC 程度の性能で動かせることの違いがあります。
少し厄介な話: オープン ソース ソフトウェアとオープン ウェイト言語モデルの違いと GPT-OSS の立ち位置について
ライセンス周りやこれらの用語の意味を正しく理解されている方は、このセクションを読み飛ばしていただいて構いません。
「オープンウェイト言語モデル」は、AI を活用する開発者がイチから言語モデルを作らなくとも、商用利用を含めて誰しもが自由に使えるものとして、学習済みの言語モデルがオープンに公開されるものです。よく、「オープン ソース ソフトウェア (OSS)」 と混同されていますが、オープン ソース ソフトウェアは必ずソース コードが公開されるのに対し、オープン ウェイト言語モデルは成果物が広く公開されるという意味では似ていますが、ほとんどの場合「どのように学習させたか」などの設計までは公開されません。
また、ライセンスの面でも違いがあります。オープン ソース ソフトウェアの場合は Apache 2.0 ライセンスや MIT ライセンスなどが使用されており、ライセンスの継承 (元のライセンスと同じ利用制限で再公開すること) や、オープン ソース ソフトウェアを使用していることのクレジット (●● を使用していますなどの文言表記) などこそ要求されるものの、それらのルールさえ守れば比較的自由に利用ができることが特徴です。
一方、オープン ウェイト言語モデルは、Meta (旧 Facebook) 社がリリースしている LLaMA というローカルな言語モデルは独自ライセンス条項で商用利用不可と定めているなど、必ずしも誰しもが自由に使えるとは限らないことに注意が必要です。そういった意味では、従来のプログラム・ソフトウェアでいう「フリーソフトウェア」あたりの感覚に近いところかもしれません。
GPT-OSS は、名称に「OSS」と含んでこそはいますが、実態はオープン ソース ソフトウェアではなく、あくまでもオープン ウェイト言語モデルです。そのため、一般的なプログラムでいうソース コードに相当する、「学習に利用したデータ群の情報」やそれらの「学習プロセス」については公開されていません。しかしながら、ほとんどの競合のオープン ウェイト言語モデルとは異なり、GPT-OSS はオープン ソース ソフトウェアでもよく使用される Apache 2.0 ライセンスで公開されているため、オープン ソース ソフトウェア的に成果物を使用できるという意味で、「OSS」と名称に含んでいるということなのだと、私は理解しています。
前提の話: 本記事における「性能」とは
さて、ようやくここからが本題です。
「GTP-OSS の性能」とひとくちに言っても、そこには様々な意味があるかと思います。生成 AI に少しでも触れたことがあるユーザーであることを前提とすれば、きっと多くの方は、「回答の精度」や「回答の生成速度 (もしくは時間)」と答えることでしょう。また、一部の方は「使いやすさ」とか「使い始めるまでが手軽であること」などと答えるかもしれません。
一旦、本記事における「性能」とは、「回答の生成速度」および「回答までに要する時間」のことを指していることとします。使いやすさや手軽さは ollama や LM Studio, もしくはその他を使うのかなどの外的要因で変動しますし、回答の質という点ではプロンプト内容で多少左右こそされるものの GPT-OSS を使う限りほぼ同等であるはずだということから、一旦本記事では考慮しないこととします。
今回のテスト環境について
今回は下記のスペック・環境にて、テストを実施しました。ただの自宅の PC です。
【PC スペック】
- Intel Core i7-12700
- NVIDIA Geforce RTX 4070 Ti (VRAM 12 GB)
- DDR4-2666 48 GB RAM (16 + 16 + 8 + 8)
- Windows 11 24H2 (26100.4770)
【ソフトウェア等】
- LM Studio 0.3.22 (Build 2)
- gpt-oss-20b
目的
LM Studio で GPT-OSS を使用するときにおいて、 LM Studio のモデル読み込みに関するコンフィグだけを変更することにより、同一ハードウェアであっても動作が速くなるケースがあるのかを調べたかったことにあります。より良い CPU や GPU を積むことで動作が速くなる傾向があることは当たり前の話ですが (一部例外はありますが) 、今のままで極限まで速く動作させたいというのは当然の欲求だと思うのです。もっとわかりやすく言えば、ゲーム用途だとカクカク、オフィス用途だとひとつ操作したら数秒待たされる…といった状況が起こったとき、それでもその環境でどうしたら快適に動かせるかと試行錯誤しようとすることと同じです。
使用したプロンプト
システム プロンプト: 指示がない限り、日本語で答えてください。
ユーザー プロンプト: Microsoft Intune で社内の Windows 11 端末を管理する場合、適用が推奨されるポリシーは何ですか。
テストの条件
下記にある LM Studio のモデル読み込みに関する設定パラメータの一部を、ひとつずつだけ変更して、各 5 回試行した平均値をとります。
Reasoning Effort の変更
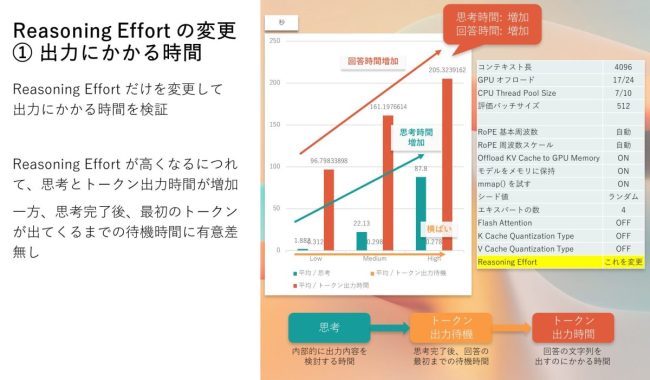
Reasoning Effort は、要するに思考にかける許容時間をどの程度にするかという設定です。Low, Medium, High の 3 種類から選択ができ、High にするとより長い思考時間を取ることになるようです。
出力にかかる時間
Reasoning Effort の説明にある通り、思考の時間 (緑色、秒) が High に近づくほど長くなっていることが分かります。トークン出力待機時間には有意な差はありませんが、回答の文字列を吐き出す時間であるトークン出力時間 (橙色、秒) も長くなっていくことが分かりました。
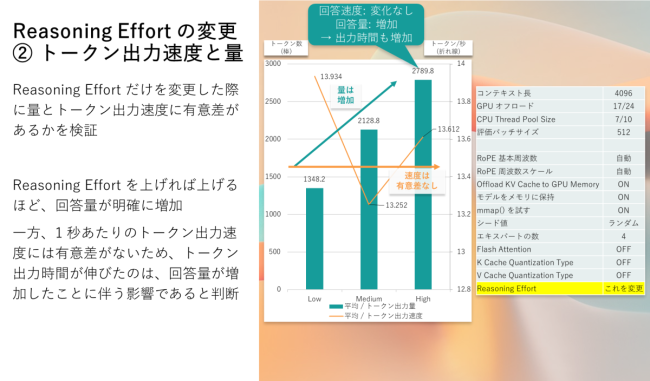
トークンあたりの出力速度
念のため、トークンあたりの出力速度の違いがあるのかも確認しました。すると、トークンあたりの出力速度 (黄色、トークン/秒) に大差なく、単純に出力トークン数 (緑色、トークン) が増加していくという傾向があったことが分かりました。
語弊が生まれることを恐れず、人間の動きに例えるならば、1 秒あたり 10 文字タイピングできることには変わりなく、しかしタイピングするべき文字の量が 1,000 文字か、2,000 文字かという違いによる、必要時間の長さの変化と同じようなものです。
GPU オフロード数の変更
GPU オフロードは gpt-oss-20b の場合は 0 – 24 の範囲で指定することができ、どこまで GPU に処理を行わせるかという設定です。なお、gpt-oss-20b は一応内蔵グラフィックのみの環境で遅いながらも動作しますが、その場合は 0 でグレーアウトして変更することができません。
ここからは Reasoning Effort を Medium に固定して、思考にかかる時間 (緑色棒、秒) とトークンあたりの出力速度 (橙色折れ線、トークン/秒) を見ていくことにします。
0, 6, 12, 17, 20, 21, 24 の 7 段階をピックアップして変更して試した結果が以下の通りです。20 までは段々思考時間が短く、トークン出力も速くなっていきました。しかし、21 になると突如として遅くなり、最大の 24 にもなると全くまともに動作せずに止まってしまいました。
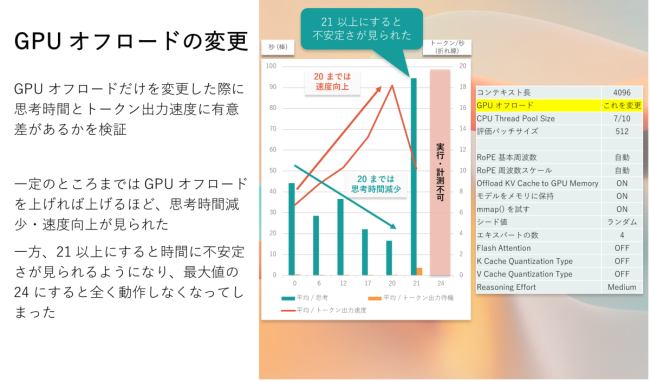
遅くなる理由を探った結果
色々探っていくうち、GPU オフロードを上げれば上げるほど、GPU の VRAM 消費量が増加することを見つけました。そして、足りない分を通常の RAM で補うような動きをするようで、GPU オフロードが 0 だと VRAM 消費量が少ない一方で RAM 消費量が多いようです。当然、RAM より VRAM の方が高速であることが、GPU オフロードを増加させて VRAM に依存を強めるほど高速になることの裏付けになると考えています。
しかし、PC スペックのところにも記載しましたが、RTX 4070 Ti を搭載しており、VRAM が 12 GB しかありませんでした。GPU オフロードを 21 にしたあたりで VRAM 使用量が 11.7 GB と上限値に最接近して頭打ちとなりました。つまり、ここで VRAM が溢れたということになります。VRAM が溢れた分、RAM 周りの I/O 処理に遅延などの問題が発生し、出力速度の不安定化や、出力の停止につながったのではないかと判断しました。
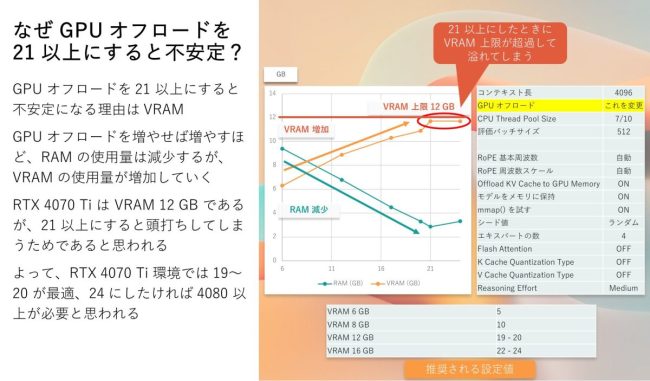
よって、ここは PC に搭載されている VRAM の容量に応じて変化させる必要がある項目であり、RTX 4070 Ti の場合は 19 または 20 が最適であるという結論に至りました。24 にするには、恐らく VRAM 16 GB 以上が必要であると思われ、具体的にはもうひとつ上の RTX 4080 などが必要になるかと思われます。
評価バッチ サイズの変更
LM Studio の設定における説明によると、「一度に処理する入力トークン数。これを増やすとパフォーマンスが向上しますが、メモリ使用量も増加します。」とあったが、思考時間・トークン出力速度ともに有意な変化は見られなかったと判断しました。

CPU Thread Pool Size の変更
特に LM Studio の設定における説明がないが、CPU の計算スレッド数を指定する項目なのではないかと推察しています。既定値は 7 ですが、この数値を小さくすると思考時間やトークン出力速度に劣化が認められました。一方で、この数値を大きくしてもそれほど変化が認められなかったため、特に変更する必要がない項目だと判断しました。

結論
私のマシンで最適な設定値
上記の結論から、少なくとも、私の今のマシンで gpt-oss-20b が最速で動いたのはこのような設定値となりました。
- GPU オフロード: 20 / 24
- CPU Thread Pool Size: 7 / 10
- 評価バッチサイズ: 512
でも結局…
gpt-oss-20b を本当に快適に動かすのであれば、VRAM 16 GB 以上の GPU を用意しよう! という結論に至ります。今であれば、RTX 5070 Ti でもいいですし、RTX 5080 があれば十分かと思います。
もし、イチから PC を組むのであれば、他のパーツの選定次第ではありますが、合計 40 – 50 万円くらいの予算をターゲットにして PC を組むと良いでしょう。ついでにこれだけあれば PC ゲームも快適、そう考えると高いけど高くないというところかとは思います。